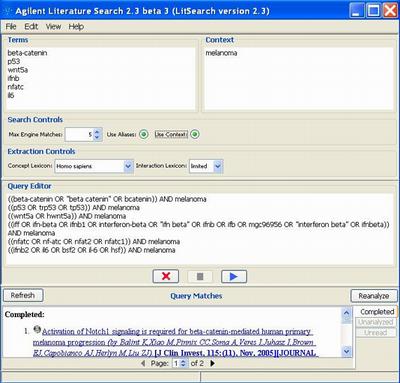
Agilent Literature Search Software provides an easy-to-use interface to its powerful querying capabilities. When a query is entered, it is submitted to multiple user-selected search engines, and the retrieved results (documents) are fetched from their respective sources. Each document is then parsed into sentences and analyzed for protein-protein associations. Agilent Literature Search Software uses a set of "context" files (lexicons) for defining protein names (and aliases) and association terms (verbs) of interest. Associations extracted from these documents are then converted into ALFA relations, which are further grouped into an ALFA network. The sentences and source hyperlinks for each association are further stored as attributes of the corresponding ALFA relations.
安捷伦出品的文献检索工具,Cytoscape软件的插件。